2021年度の介護報酬改定項目の中に、興味深い項目があります。それは、「CHASE・VISIT情報の収集・活用とPDCAサイクルの推進」という項目で、「令和3年度介護報酬改定における主な改定事項について」という資料のスライド28~30に記載されています。
出典元:https://www.mhlw.go.jp/content/12300000/000727135.pdf#page=29
科学的介護のためのデータベース
この項目では、「介護関連データの収集・活用及びPDCAサイクルによる科学的介護を推進していく観点から、全てのサービス(居宅介護支援を除く)について、CHASE・VISITを活用した計画の作成や事業所単位でのPDCAサイクルの推進、ケアの質の向上への取組を推奨する。居宅介護支援については、各利用者のデータ及びフィードバック情報のケアマネジメントへの活用を推奨する。」とされています。
ここで、VISITとは、通所・訪問リハビリテーションの質の評価データ収集等のためのデータベース、CHASEとは、高齢者の状態・ケアの内容のデータベースのことであり、具体的な内容は、次のようなものとされています。
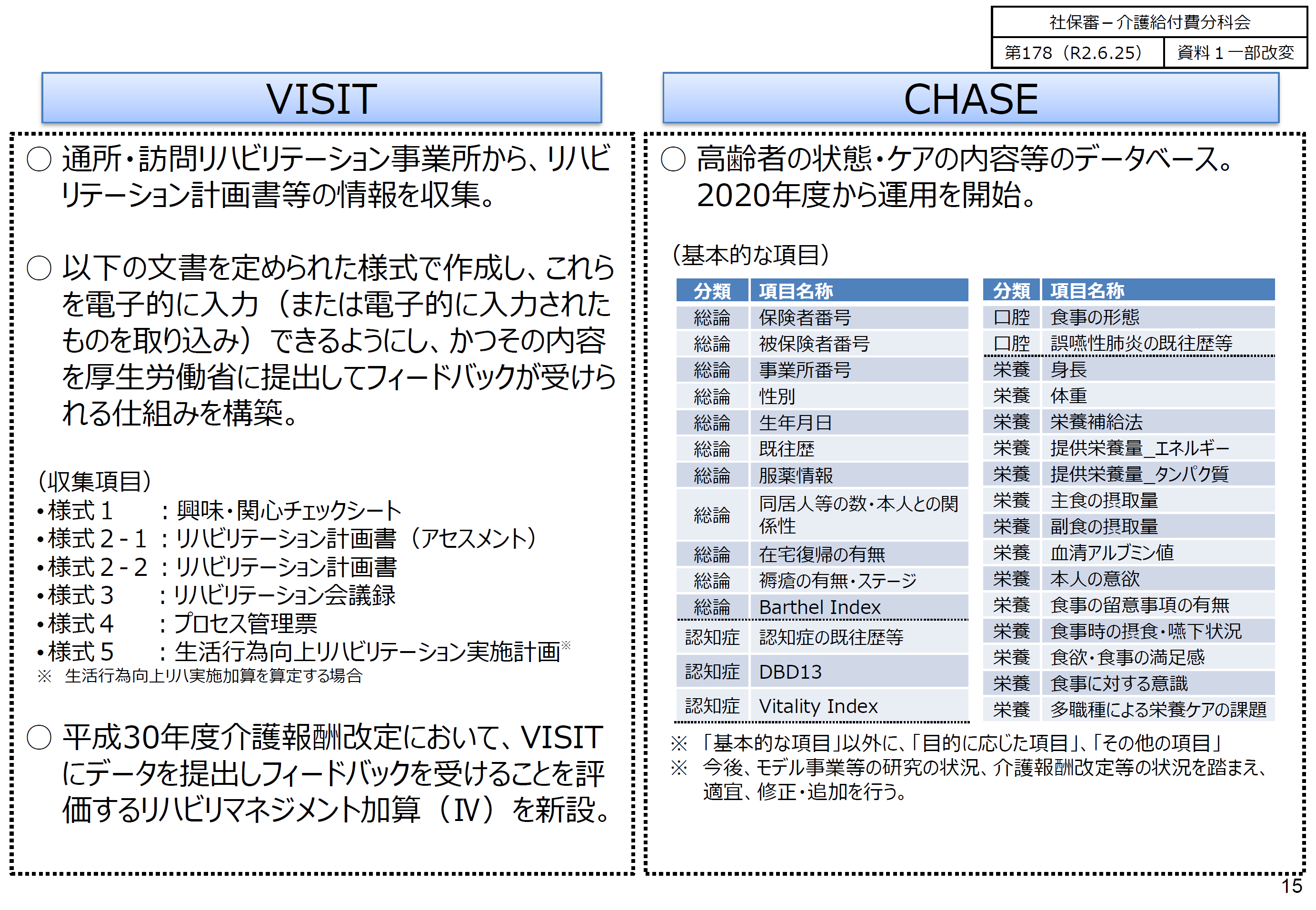
https://www.mhlw.go.jp/content/12300000/000672514.pdf#page=16
要すれば、介護の質を科学的に高めていくために、介護及び要介護者の状態についてのデータを日本全体でデータベース化し、それらのデータを解析していこうとしているのです。
上のCHASEに記録される項目例には含まれていませんが、このCHASEに登録すべきデータをどうするかを検討していた「介護分野における今後のエビデンスの蓄積に向けて収集すべき情報について(中間とりまとめ)」では、「掃除・整理整頓」について、「興味がある・してみたい・しているそれぞれの該当・非該当を入力」したり、「時間管理はできますか」について、「0 できない、1 できる、9 不明」と入力したりすることが想定されています。
子どもの発達に関するデータ収集の困難性
このようなデータを全国的に収集して解析し、サービスの質を高めていこうという発想は、子どもの発達を支援する保育の分野でも、必要なのではないでしょうか。
目下、子どもの発達記録の分析方法を検討するなかで、専門の研究者が継続的に子どもの発達に関するデータを収集することに困難を覚えていることが見えてきました。そして、子どもの発達に関するデータ収集の困難性から、発達を測定するスケール、物差しの開発も難しいという話しも耳にします。子どもの発達スケールを開発するには、相当なサンプル数を継続的に確保することが必要で、多くの研究者の方は、個々の力では難しいと判断しているようです。結果的に、子どもの発達に関するデータ収集は、発達障害検出のために行われるものや、個別の研究目的のための限定的なものになってしまうようです。
データ収集の前提としての『共通言語』:ICF
とはいえ、闇雲に子どもの発達に関するデータを集めても、分析に活用できるデータベースになる分けではありません。介護分野において、報酬加算という優遇措置まで講じて日本全体をカバーするデータ整備が可能なのは、勿論データベース整備の検討を数年かけて検討してきたこともありますが、データ蓄積の基盤ができていたからであることを看過することはできません。
その介護に関する「データ蓄積の基盤」とは、WHOで設定されたICFであり、これは、厚生労働省によって「国際生活機能分類」と呼ばれており、「健康状態と健康関連状況について、統一的で標準的な言語と概念的枠組みを提供することを目的としている分類であり、すべての人の健康状態を全人的に把握するためのもの」(厚生労働省大臣官房統計情報部「生活機能分類の活用に向けて(案)」https://www.mhlw.go.jp/shingi/2007/03/dl/s0327-5l.pdf 2ページ)とされています。
つまり、介護対象の方の状態把握をするための「共通言語」として位置づけられ、その活用により、
○ 当人やその家族、保健・医療・福祉等の幅広い分野の従事者が、ICFを用いることにより、生活機能や疾病の状態についての共通理解を持つことができる。
○ 生活機能や疾病等に関するサービスを提供する施設や機関などで行われるサービスの計画や評価、記録などのために実際的な手段を提供することができる。
○ 調査や統計について比較検討する標準的な枠組みを提供することができる。
などが期待されています(同 5ページ)。
介護の分野で、オールジャパンのデータベースを構築できるのは、被介護者の健康状態についての概念の共通化が図られており、データベースに入力するデータの共通化を図ることが可能になっているからです。
日本の「子どもの発達分類」のススメ
科学的で、個別に最適化された「子どもの発達」のサポートを実現していくためには、データ解析が、間違いなく必要で、そのためには、データの蓄積が必要です。
その前提として、そのデータを幅広く用いてくためには、「子どもの発達」状態(発達過程)についても、定型発達を「堅く」つくるということではなく、子どもの発達という現象を共通言語で表現、記録できるような基盤を整備する、いわば、日本の「子どもの発達分類」から構想していくことが必要なのだと思います。
ちなみに、看護分野では、NANDA-I-NIC-NOCという分類体系が実務で用いられています。NANDA-Iは看護診断分類、NICは看護介入分類、NOCは介護成果分類として、被看護者の状態把握、看護手法、看護の目標が体系的に分類する仕組みができており、これらの分類が、電子カルテ上で利活用できるシステムも実運用されています。
このような看護や介護というヘルスケア分野の先行実践を見つつ、保育、子どもの発達の分野におけるデータ基盤の整備について研究を深めていく機運が高まることを期待したいですし、そのための取組を進めていきたいと思っています。